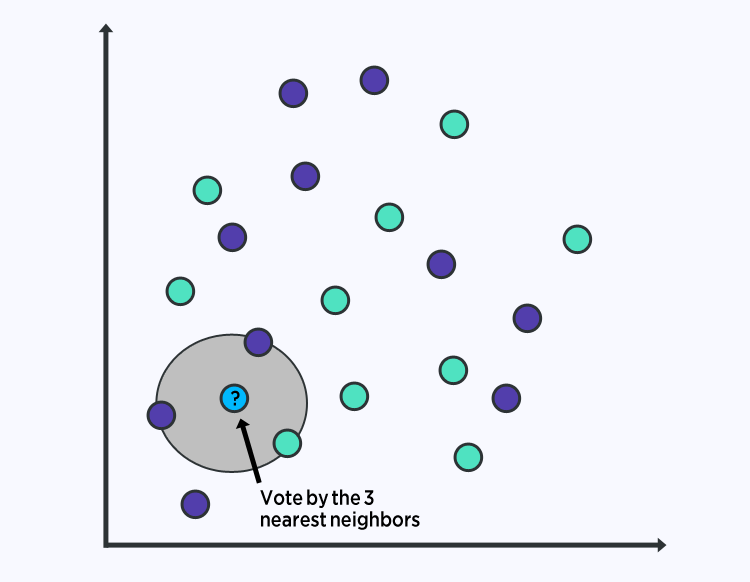
prediction for new data point is done by searching the dataset for the most similar instances (neighbors) and summarizing the output variable for those K instances. For regression problems: the mean output variable For classification problems: mode (or most common) class value.
determinining the similarity between the data instances: Euclidian Distance - if your attributes are all of the same scale (all in inches for example) use the Euclidean distance, a number you can calculate directly based on the differences between each input variable.
Cons
Require a lot of memory to store all the data Distance can brea down in high dimensions (curse of dimensionality)